This is one of those you had to be there moments. If you come into the world of data and analytics engineering today, ELT is just what it is and is pretty much universally understood. But if you’ve been around for …waves hands… longer than that, you might be confused by what people are calling ELT and ETL. Well, I was ✋.
As SeattleDataGuy put it when I shared my previous article:
ELT vs ETL vs E(t)LT vs ᵉ𝓛ᴛⷮ🅔Eͤᵗᴸ (I made the last one up—I hope) #
My starting point for understanding ETL and ELT is what I already knew from a decade ago. The de facto approach to building a datawarehouse had been ETL. You’d run an ETL server with something like Informatica PowerCenter, which would Extract the data from a source system, Transform it, and then Load it to the target datawarehouse.
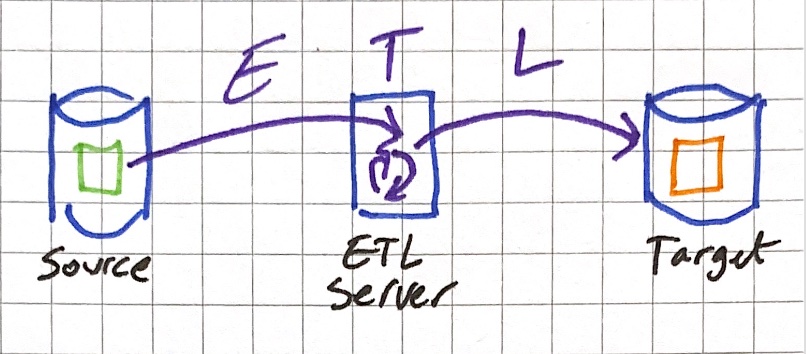
Then Oracle Data Integrator (neé Sunopsis) came along and introduced the concept of ELT, in which the data is Extracted from source, and then Loaded to the target datawarehouse. The difference here is that its loaded in its [usually] raw form, and then Transformed. The benefit of this ELT (or E-LT to spell it out a bit more clearly) approach is that instead of having to provision and scale an ETL server to do the heavy lifting of transformation work you can get the database to do it. Databases are particularly good at crunching large sets of data - so this makes a lot of sense.

ELT Is Exactly As You Knew It—Except Not At All #
The huge boulder that I just couldn’t make the mental leap over when I started getting back into this stuff was if ELT was where it was at, where dbt fitted into the picture.

The mistake I was making was assuming that it was a 1:1 substitute for an existing tool - whereas it’s not. dbt does the T of ELT. That’s all.
So ELT is still ELT, it’s just that in terms of tooling it’s become (EL)(T).
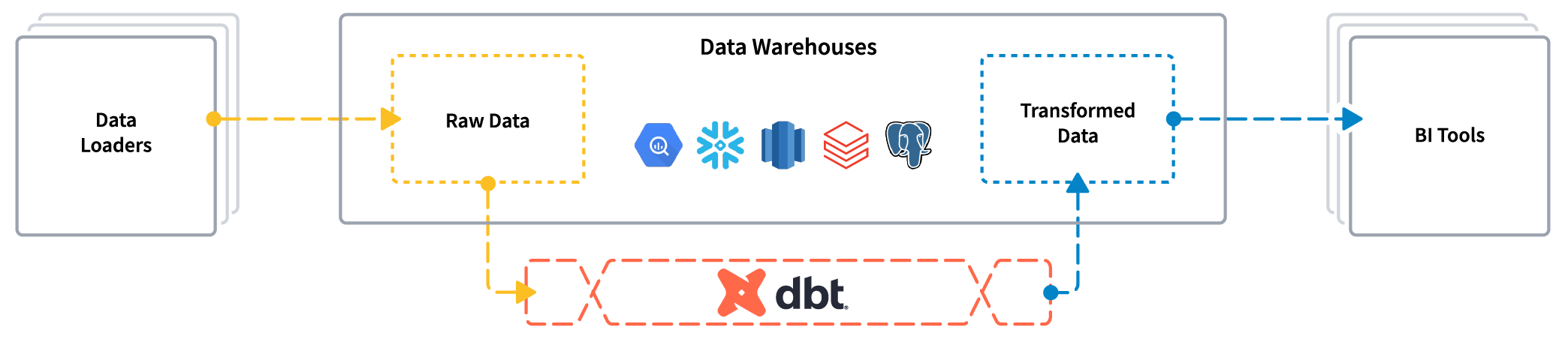
$Tool_1 does the Extract and Load of raw data from a source into a stage in the target data warehouse/lake (e.g. S3, BigQuery, Snowflake - heck, even Oracle!). Possibly does some very light transformation work on the way. Tools in this space include FiveTran, Singer, AirByte, and others - it’s a crowded space with each vendor having its own spin.
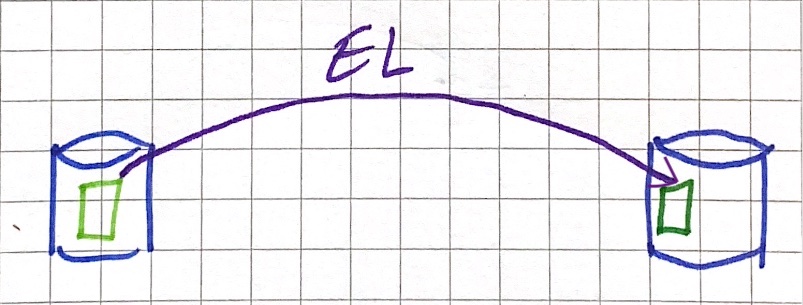
Regardless of how the data gets loaded, $Tool_2 (dbt being the obvious one here) then Transforms the data in place. In the context of something like Oracle that’s going to be two schemas on the same instance. Other stacks will have their own implementations. When you think of something like S3 and Spark the concept becomes rather abstract - but it’s still the same principle: read the data, transform the data, write it back to the same storage.

dbt’s own repo spells it out nicely too - here it is with my EL and T annotations added:
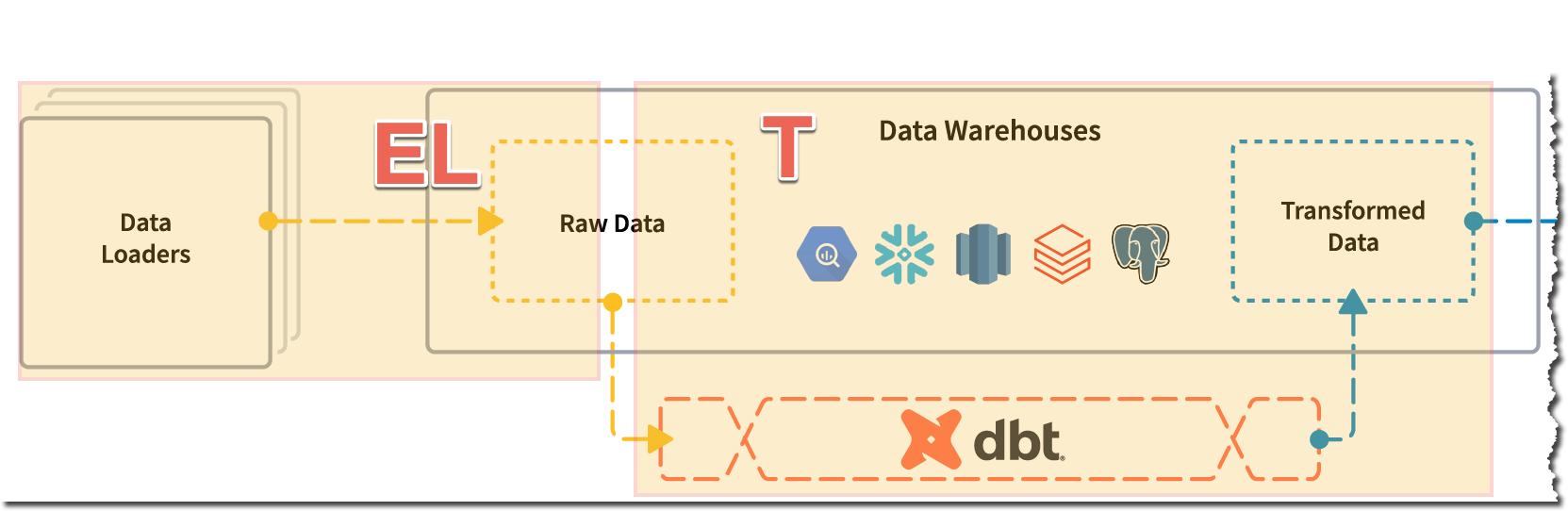
Simple? Mostly. Marketing Bollocks? Not entirely. #
Another nuance to what I described above is discussed in this thread started by Eric Sammer
Here's how you know ELT vs. ETL is just marketing cruft - many "ELT" products are actually ETL products (they do the T before the L, outside of the database).
— Eric Sammer (@esammer) September 7, 2022
Sorry ELT die-hards. You're probably doing ETL(T). It's cool. Life's complicated.
The 💡 statement is this one from TJ
Describing where the business logic transformation lives is the critical distinction.
— // teej // (@teej_m) September 7, 2022
TJ also quotes James Densmore from last year:
ELT is not just ETL rebranded. It's a total paradigm shift made possible by modern data warehouses and cloud infra.
— @jamesdensmore@data-folks.masto.host (@jamesdensmore) March 3, 2021
There's still some transform that happens after the "E", just not biz logic or data modeling. I refer to it as EtLT in my book, but I usually just say ELT 😀 pic.twitter.com/9gajlJLlpV
From this I took the point that ETL/ELT is not just about where the work gets executed, but also about what gets executed, namely the business logic. By extension it is also about who is responsible for it (and by further extension, to whom the supporting tools need to be targetted at supporting).
So the "datawarehouse engineers" of yore would build the pipeline including transformations all in one:
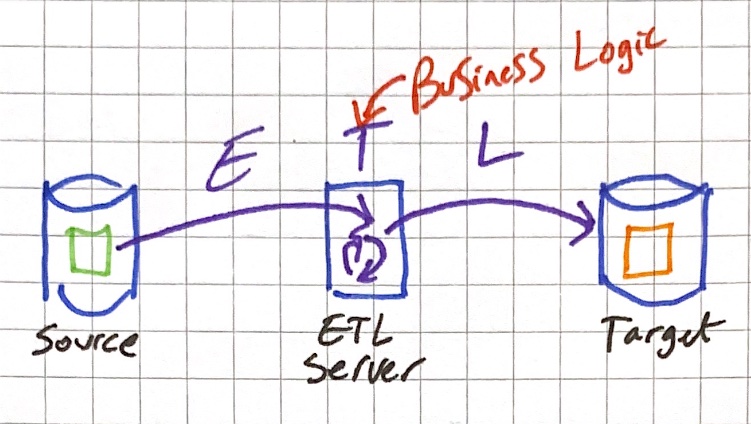
Whereas nowadays we have the pipeline built by one person (perhaps the "data engineer"):

And then the "analytics engineers" (broadly) write code in dbt et al to apply transformations to the data:

Reference Architectures #
OK, so that’s my confusion over ETL/ELT cleared up. It’s as it was before, but with added nuance and separate toolsets today. My next point of interest was looking at how approaches to the stages of data handling, including in published reference architectures for data at a high level compared.
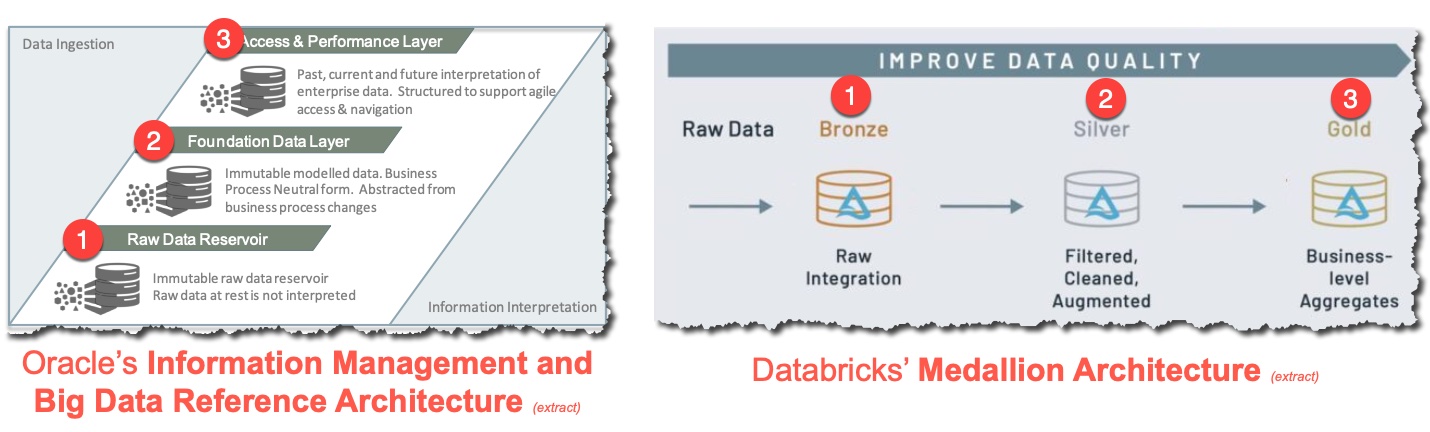
You see, some things change…and some things stay the same. 9 years ago Oracle published their reference archicture for Information Management and Big Data. Whilst bits of it haven’t aged so well, the core concept of how data is sourced, stored, and served seems to match up almost exactly with Databricks' "Medallion Architecture". Which is a good thing - trends come and go but if as an industry we’ve settled on a common approach then it makes everyone’s lives easier!
| 2013 | 2022 | tl;dr |
|---|---|---|
|
|
The data from the source system. In its raw state or extremely lightly transformed. |
|
|
Clean and process the data into a normalised set of tables. The resulting data forms the basis of specific processing done by one or more users of the data in the next stage. |
|
|
Data is transformed into business-specific slices. Could be denormalised and/or aggregated for performance and ease of use. |
Data Engineering in 2022 #
Check out my other posts in this series 👇️
-
Query & Transformation Engines [TODO]

{kind=link}